Строки¶
Питон хорошо приспособлен для работы с текстовой информацией. В нём есть много операций для работы со строками, несколько способов записи строк (удобных в разных случаях). В современных версиях питона (3.x) строки юникодные, т.е. они могут содержать одновременно русские и греческие буквы, немецкие умляуты и китайские иероглифы.
s='Какая-нибудь строка \u00F6 \u03B1'
print(s)
'Эта строка может содержать " внутри'
"Эта строка может содержать ' внутри"
s='Эта содержит и \', и \"'
print(s)
s="""Строка,
занимающая
несколько
строчек"""
print(s)
s=="Строка,\nзанимающая\nнесколько\nстрочек"
Несколько строковых литералов, разделённых лишь пробелами, слипаются в одну строку. Подчеркнём ещё раз: это должны быть литералы, а не переменные со строковыми значениями. Такой способ записи особенно удобен, когда ружно передать длинную строку при вызове функции.
s='Такие ' 'строки ' 'слипаются'
print(s)
print('Такие\n'
'строки\n'
'слипаются')
В питоне нет специального типа char, его роль играют строки длины 1. Функция ord возвращает (юникодный) номер символа, а обратная ей функция chr возвращает символ (строку длины 1).
n=ord('а')
n
chr(n)
Функция len возвращает длину строки. Она применима не только к строкам, но и к спискам, словарям и многим другим типам, про объекты которых разумно спрашивать, какая у них длина.
s='0123456789'
len(s)
Символы в строке индексируются с 0. Отрицательные индексы используются для счёта с конца: s[-1] - последний символ в строке, и т.д.
s[0]
s[3]
s[-1]
s[-2]
Можно выделить подстроку, указав диапазон индексов. Подстрока включает символ, соответствующий началу диапазона, но не включает соответствующий концу. Удобно представлять себе, что индексы соответствуют положениям между символами строки. Тогда подстрока s[n:m] будет расположена между индексами n и m.
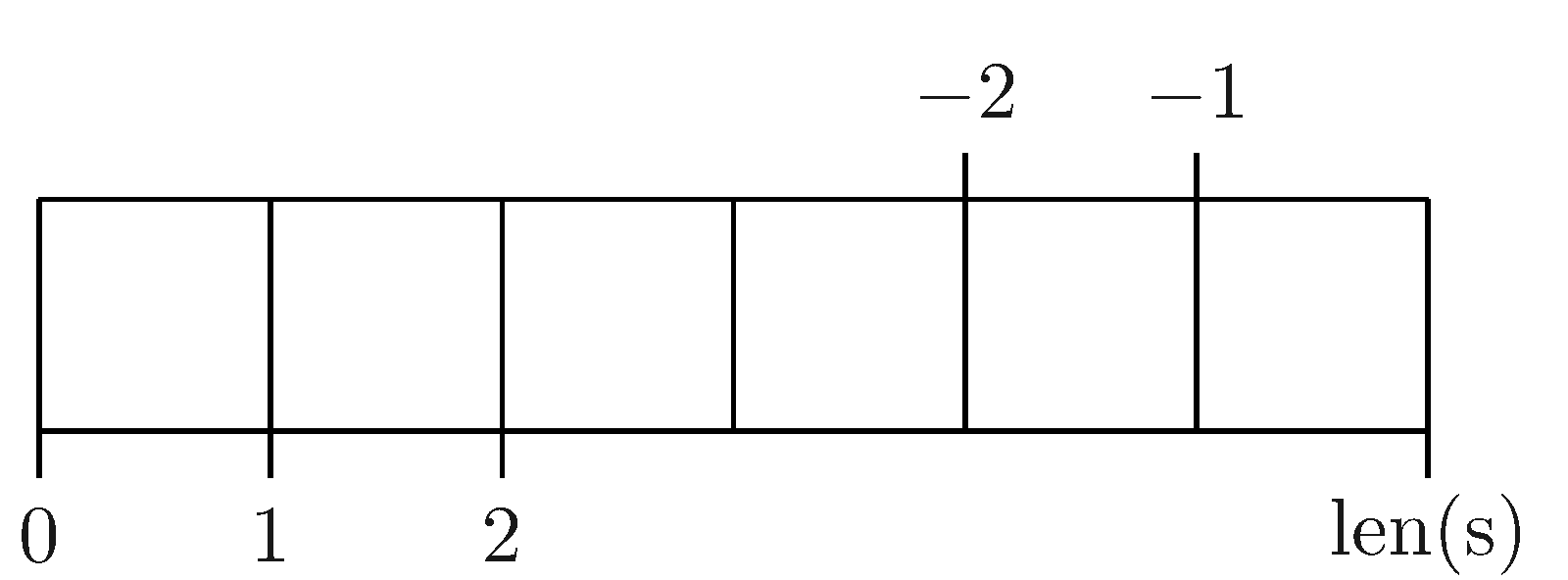
s[1:3]
s[:3]
s[3:]
s[:-1]
s[3:-2]
Если не указано начало диапазона, подразумевается от начала строки; если не указан его конец - до конца строки.
Строки являются неизменяемым типом данных. Построив строку, нельзя изменить в ней один или несколько символов. Операции над строками строят новые строки - результаты, не меняя своих операндов. Сложение строк означает конкатенацию, а умножение на целое число (с любой стороны) - повторение строки несколько раз.
s='abc'; t='def'
s+t
s*3
Операция in проверяет, содержится ли символ (или подстрока) в строке.
'a' in s
'd' in s
'ab' in s
'b' not in s
У объектов типа строка есть большое количество методов. Метод lstrip удаляет все whitespace-символы (пробел, tab, newline) в начале строки; rstrip - в конце; а strip - с обеих сторон. Им можно передать необязательный аргумент - символы, которые нужно удалять.
s=' строка '
s.lstrip()
s.rstrip()
s.strip()
lower и upper переводят все буквы в маленькие и заглавные.
s='СтРоКа'
s.lower()
s.upper()
Проверки: буквы (маленькие и заглавные), цифры, пробелы.
'АбВг'.isalpha()
'абвг'.islower()
'АБВГ'.isupper()
'0123'.isdigit()
' \t\n'.isspace()
Строки имеют тип str.
type(s)
s=str(123)
s
n=int(s)
n
int('123x')
x=float('123.456E-7')
x
Часто требуется вставить в строку значения каких-нибудь переменных (или выражений). Такие строки особенно полезны для печати сообщений. Для этого используются форматные строки: в них в фигурных скобках можно писать выражения, они вычислятся, и их значения подставятся в строку.
f's = {s}, n = {n}, x = {x}'
После выражения можно поставить знак : и указать некоторые детали того, как это значение должно печататься. В частности, можно задать ширину поля (т.е. число символов). Если значение не влазит в эту ширину поля, для его печати будет использовано больше символов - столько, сколько надо, чтобы напечатать это значение полностью.
print(f'"{s:5}" "{n:5}" "{x:5}"')
Целые числа можно печатать в десятичном, шестнадцатиричном или двоичном виде.
print(f'десятичное "{n:5d}", 16-ричное "{n:5x}", двоичное "{n:5b}"')
Для чисел с плавающей точкой можно задать число цифр после точки и формат с фиксированной точкой или экспоненциальный.
print(f'{x:10.5f} {x:10.5e} {1/x:10.5f} {1/x:10.5e}')